整个DQN的实现分为两部分,第一部分是用纯Q-learning的表格形式训练Agent,第二部分是DQN算法,结合深度学习,用网络进行Q值更新。
Agent环境
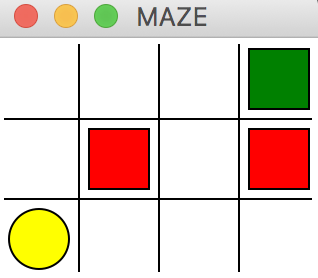
首先,我们需要虚拟一个环境,这里以走迷宫为例。黄色圆圈代表Agent,红色方块表示地雷区域,绿色表示终点。
GYM是一个通用的强化学习实验环境,是OPEN AI的一个开源项目。为了了解OPEN AI的gym环境,此简易迷宫环境的代码参照了gym中游戏的API,实现了reset、step和render方法。以下为env.py文件实现代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
import time
import sys
import numpy as np
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
WIDTH = 4
HEIGHT = 3
UNIT = 40
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('MAZE')
self.geometry('{0}x{1}'.format(WIDTH*UNIT, HEIGHT*UNIT))
self._build_maze()
def _create_object(self, center_x, center_y, size, shape='oval', color='yellow'):
"""create different object of maze including robot, bomb and treasure
"""
if(shape.lower() == 'oval'):
object = self.canvas.create_oval(
center_x - size, center_y - size,
center_x + size, center_y + size,
fill=color
)
elif(shape.lower() == 'rectangle'):
object = self.canvas.create_rectangle(
center_x - size, center_y - size,
center_x + size, center_y + size,
fill=color
)
return object
def _build_maze(self):
"""draw maze including the whole map and different objects
"""
self.canvas = tk.Canvas(self, bg='white', width=WIDTH*UNIT, height=HEIGHT*UNIT)
for c in range(0, WIDTH * UNIT, UNIT):
x0, y0, x1, y1 = c, 0 ,c , HEIGHT * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, HEIGHT * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, WIDTH * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
self.origin = np.array([20, 20]) # center
self.robot_center = self.origin + np.array([0, UNIT*2])
self.robot_size = 15
self.robot = self._create_object(
self.robot_center[0], self.robot_center[1], self.robot_size,
shape='oval', color='yellow'
)
bomb1_center = self.origin + UNIT
bomb_size = 15
self.bomb1 = self._create_object(
bomb1_center[0], bomb1_center[1], bomb_size,
shape='rectangle', color='red'
)
bomb2_center = self.origin + np.array([UNIT * 3, UNIT])
self.bomb2 = self._create_object(
bomb2_center[0], bomb2_center[1], bomb_size,
shape='rectangle', color='red'
)
treasure_center = self.origin + np.array([UNIT * 3, 0])
treasure_size = 15
self.treasure = self._create_object(
treasure_center[0], treasure_center[1], treasure_size,
shape='rectangle', color='green'
)
self.canvas.pack()
# self.canvas.wait_window() # preview maze
def reset(self):
"""reset the game, init the coords of robot
"""
self.update()
time.sleep(0.5)
self.canvas.delete(self.robot)
self.robot = self.create_object(
self.robot_center[0], self.robot_center[1], self.robot_size,
shape='oval', color='yellow'
)
return self.canvas.coords(self.robot)
def step(self, action):
"""operation of the robots and return the coords of robo, reward and final state
"""
s = self.canvas.coords(self.robot)
base_action = np.array([0, 0])
if action == 0:
if s[1] > UNIT:
base_action[1] -= UNIT # up
elif action == 1:
if s[1] < (HEIGHT - 1) * UNIT:
base_action[1] += UNIT # down
elif action == 2:
if s[0] < (WIDTH - 1) * UNIT:
base_action[0] += UNIT # right
elif action == 3:
if s[0] > UNIT:
base_action[0] -= UNIT # left
self.canvas.move(self.robot, base_action[0], base_action[1])
s = self.canvas.coords(self.robot) # next coords
if s == self.canvas.coords(self.treasure):
reward = 1
done = True
s = 'terminal'
print('Mission complete')
elif s == self.canvas.coords(self.bomb1) or s == self.canvas.coords(self.bomb2):
reward = -1
done = True
s = 'terminal'
print('boom! failed!')
else:
reward = 0
done = False
return s, reward, done
def render(self):
time.sleep(0.1)
self.update()
Q-Learning实现
算法实现:
纯Q-learnning方法不需要使用深度学习的神经网络,Q-learning通过每一步获取的reward不断更新每个Q(S, A),使用e-greedy策略选取action。
根据以上env环境,在q_learning.py中实现Q-learning算法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import numpy as np
import pandas as pd
class QLearning:
def __init__(self, actions, learning_rate=0.01, discount=0.9, e_greedy=0.1):
self.actions = actions
self.alpha = learning_rate
self.gamma = discount
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float32)
# print(self.q_table)
def check_state_exist(self, state):
if state not in self.q_table.index:
self.q_table = self.q_table.append(pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state
)) # use state as the name of df's index
def choose_action(self, state):
self.check_state_exist(state)
if np.random.uniform() < self.epsilon:
action = np.random.choice(self.actions)
else:
"""
if the state in the table, pick the action_value of the state
e.g. state = 2, state_action = df.loc[2, :] = [1,2,3,4,5]
permutation = [2,3,1,0,4] -> state_action = [3, 4, 2, 1, 5]
action = state_action.idxmax() = 4
"""
state_action = self.q_table.loc[state, :]
state_action = state_action.reindex(np.random.permutation(state_action.index)) # shuffle
action = state_action.idxmax()
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max()
else:
q_target = r
self.q_table.loc[s, a] += self.alpha * (q_target - q_predict)
Agent训练
有了以上的环境env和学习算法q_learning,我们就可以将两部分结合起来训练我们的Agent了。以下是play.py代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from env import Maze
from q_learning import QLearning
def update():
for episode in range(100):
state = env.reset()
step_count = 0
while True:
env.render()
action = RL.choose_action(str(state))
state_, reward, done = env.step(action)
step_count += 1
RL.learn(str(state), action, reward, str(state_))
state = state_
if done:
print(' Round over at: {0} round, Total steps: {1} steps'.format(episode, step_count))
break
env.distroy()
if __name__ == '__main__':
env = Maze()
RL = QLearning(actions=list(range(env.n_actions)))
env.after(100, update())
env.mainloop()
print('\n Q Table')
print(RL.q_table)